





@ 基于Hadoop平台的哈姆雷特词频统计设计
基于Hadoop平台的哈姆雷特词频统计设计
发布日期:2022-02-27 19:33 点击次数:133
摘要Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统,简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。本课程设计学习Hadoop的基本概念如MapReduce、HDFS等,同时搭建Hadoop平台进行相应的设计,掌握在LINUX下常用命令,并掌握Hadoop的基本操作;通过MapReduce编程,以哈姆雷特为研究对象,进行词频统计,统计单个或者多个文本文件中每个词汇出现的次数;并且了解Hadoop分布式文件系统(HDFS)是hadoop上部署的存储架构,熟练应用Hadoop对HDFS文件进行创建和读写;以及利用HDFS文件系统开放的API对HDFS系统进行文件的创建和读写。通过本课程设计,建立起对Hadoop云计算的初步了解,最后通过Hadoop平台实现结果的显示。关键词:hadoop,MapReduce,云计算,hdfs一、 前言本课程设计要求学生学习Hadoop的基本概念如MapReduce、HDFS等,搭建Hadoop平台进行相应的设计,掌握在LINUX下常用命令,并掌握Hadoop的基本操作;通过MapReduce编程,以哈姆雷特为研究对象,进行词频统计,统计单个或者多个文本文件中每个词汇出现的次数;了解Hadoop分布式文件系统(HDFS)是hadoop上部署的存储架构,熟练应用Hadoop对HDFS文件进行创建和读写等操作。通过本课程设计,建立起对Hadoop云计算的初步了解,最后通过Hadoop平台实现结果的显示。Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司。Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。二、 基本原理2.1 hadoopHadoop是一个分布式系统基础框架。什么是分布式系统?分布式系统是若干独立计算机的集合,这计算机对用户来说就像单个相关系统。也就是说分布式系统背后是由一系列的计算机组成的,但用户感知不到背后的逻辑,就像访问单个计算机一样。一个标准的分布式系统应该具有以下几个主要特征:2.1.1 分布性分布式系统中的多台计算机之间在空间位置上可以随意分布,系统中的多台计算机之间没有主、从之分,即没有控制整个系统的主机,也没有受控的从机。2.1.2 透明性系统资源被所有计算机共享。每台计算机的用户不仅可以使用本机的资源,还可以使用本分布式系统中其他计算机的资源(包括CPU、文件、打印机等)。2.1.3 同一性系统中的若干台计算机可以互相协作来完成一个共同的任务,或者说一个程序可以分布在几台计算机上并行地运行。2.1.4 通信性系统中任意两台计算机都可以通过通信来交换信息。在分布式系统中:A、应用可以按业务类型拆分成多个应用,再按结构分成接口层、服务层;我们也可以按访问入口分,如移动端、PC端等定义不同的接口应用;B、数据库可以按业务类型拆分成多个实例,还可以对单表进行分库分表;C、增加分布式缓存、搜索、文件、消息队列、非关系型数据库等中间件;很明显,分布式系统可以解决集中式不便扩展的弊端,我们可以很方便的在任何一个环节扩展应用,就算一个应用出现问题也不会影响到别的应用。分布式系统虽好,也带来了系统的复杂性,如分布式事务、分布式锁、分布式session、数据一致性等都是现在分布式系统中需要解决的难题,虽然已经有很多成熟的方案,但都不完美。分布式系统也增加了开发测试运维成本,工作量增加,分布式系统管理不好反而会变成一种负担。Hadoop包含三大核心:HDFS、MapReduce、YARN。Hadoop包含四个模块:Hadoop Common、Hadoop DFS、Hadoop MapReduce、Hadoop YARN。2.2 HDFSHDFS源自于Google的GFS论文,发表于2003年10月,HDFS是GFS的克隆版。HDFS全称Hadoop Distributed File System。是一个易于扩展的分布式文件系统,运行在大量普通廉价机上,提供容错机制,为大量的用户提供性能不错的文件存取服务。HDFS设计目标:A、存储量大B、自动快速检测应对硬件错误C、流式访问数据D、移动计算比移动数据本身更划算E、简单一致性模型F、异构平台可移植HDFS优点: A、高可靠性:Hadoop一般都在成千上万的计算机集群之上,且可以搭建Hadoop的高可靠集群,以及内部容错功能优秀。 B、高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便的扩展到数以千计的节点中。 C、高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理数据特别快。 D、高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。HDFS缺点: A、不适合低延迟数据访问 B、无法高效存储大量小文件 C、不支持多用户写入及任意修改文件HDFS三个服务:namenode、secondary namenode、datanode。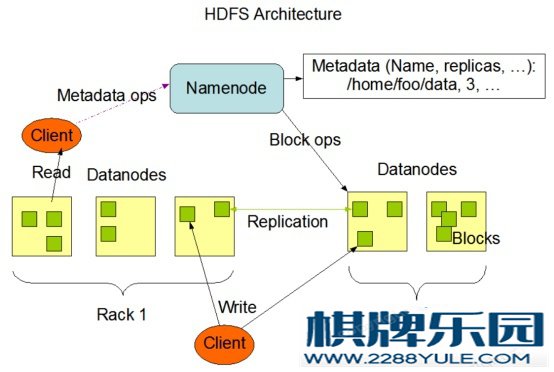
 图2-1 HDFS结构2.2.1 namenodeNamenode是一个中心服务器,单一节点,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。Namenode负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过那么namenode,只会询问它跟那个datanode联系,否则namenode会成为系统的瓶颈。副本存放在哪个datanode由namenode控制,根据全局情况作出块放置决定,读取文件时namenode尽量让用户读取最近的副本,降低带块消耗和读取时延。Namenode全权管理数据块的复制,它周期性地从集群中的每个datanode接收心跳信号和块状态宝报告(blockreport)。接收到心跳信号意味着DataNode节点工作正常。块状态报告包含了一个该DataNode上所有数据块的列表。包含了两个核心的数据结构,FsImage和EditLog。FsImage:用于维护整个文件系统数以及文件树中所有的文件和文件夹的元数据EditLog:记录了所有针对文件的创建,删除,重命名等操作2.2.2 Secondary NameNode为主namenode内存中的文件系统元数据,创建检查点,在文件系统中设置一个检查点来帮助NameNode更好的工作,不是取代掉NameNode,也不是备份SecondayName有两个作用一是镜像备份,二是日志与镜像的定期合并。两个同时进行称为checkpoint。镜像备份的作用:备份fsImage合并作用:防止如果NameNode节点故障,namenode下次启动时,会把fsImage加载到内存中,应用editLog,EditLog往往很大,可以减少重启时间,同时保证HDFS系统的完整性。2.2.3 datanodeDatanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。Datanode以存储数据块(Block)的形式保存HDFS文件。响应客户端的读写文件请求。定期向NameNode汇报心跳信息、数据块汇报信息(BlockReport )、缓存数据块汇报信息(CacheReport)增量数据块块汇报信息。响应NameNode返回的指令,如复制、删除、创建数据块指令。2.3 MapReduce2.3.1 MapReduce概念MapReduce将整个并行计算过程抽象到两个函数: A、Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。 B、Reduce(化简 归约):对一个列表的元素进行合并。一个简单的MapReduce程序只需要指定map()、reduce()、input和output,剩下的事由框架完成。MapReduce特点: A、易于编程 B、良好的扩展性 C、高容错性 D、适合PB级以上海量数据的离线处理相关概念: A、Job:用户的每一个计算请求,称为一个作业。 B、Task:每一个作业都需要拆开,交由多个服务器来完成,拆分出来的执行单位,就称为任务。YARN设计目标: A、通用的统一资源管理系统:同时运行长应用程序和短应用程序。 B、长应用程序:理论上永不停止运行,Service,http service等 C、短应用程序:短时间内会运行结束的程序,MR job,Spark job等。YARN服务组件: A、Client B、ResourceManager、Applicaton Master C、NodeManager、ContainerYARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave。2.4.1 ResourceManagerResourceManager负责对各个NodeManager上的资源进行统一管理和调度。整个集群只有一个。功能: A、处理客户端请求 B、启动/监控ApplicationMaster C、监控NodeManager D、资源分配与调度2.4.2 NodeManager整个集群有多个,负责单节点资源管理和使用。功能: A、单个节点上的资源管理和任务管理 B、处理来自ResourceManager的命令 C、处理来自ApplicationMaster的命令NodeManager管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态。2.4.3 Application Master管理一个在YARN内运行的应用程序的每个实例功能: A、数据切分 B、为应用程序申请资源,并进一步分配给内部任务 C、任务监控与容错Applicaton Master负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务。2.4.4 ContainerYARN的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。功能: A、对任务运行环境的抽象 B、描述一系列信息 C、任务运行资源(节点、内存、CPU) D、任务启动命令 E、任务运行环境三、 系统分析3.1 HDFS-文件存储结构3.1.1 读数据Client -> NameNodeClient -> DataNode3.1.2 写数据Client -> NameNode
图2-1 HDFS结构2.2.1 namenodeNamenode是一个中心服务器,单一节点,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。Namenode负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过那么namenode,只会询问它跟那个datanode联系,否则namenode会成为系统的瓶颈。副本存放在哪个datanode由namenode控制,根据全局情况作出块放置决定,读取文件时namenode尽量让用户读取最近的副本,降低带块消耗和读取时延。Namenode全权管理数据块的复制,它周期性地从集群中的每个datanode接收心跳信号和块状态宝报告(blockreport)。接收到心跳信号意味着DataNode节点工作正常。块状态报告包含了一个该DataNode上所有数据块的列表。包含了两个核心的数据结构,FsImage和EditLog。FsImage:用于维护整个文件系统数以及文件树中所有的文件和文件夹的元数据EditLog:记录了所有针对文件的创建,删除,重命名等操作2.2.2 Secondary NameNode为主namenode内存中的文件系统元数据,创建检查点,在文件系统中设置一个检查点来帮助NameNode更好的工作,不是取代掉NameNode,也不是备份SecondayName有两个作用一是镜像备份,二是日志与镜像的定期合并。两个同时进行称为checkpoint。镜像备份的作用:备份fsImage合并作用:防止如果NameNode节点故障,namenode下次启动时,会把fsImage加载到内存中,应用editLog,EditLog往往很大,可以减少重启时间,同时保证HDFS系统的完整性。2.2.3 datanodeDatanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。Datanode以存储数据块(Block)的形式保存HDFS文件。响应客户端的读写文件请求。定期向NameNode汇报心跳信息、数据块汇报信息(BlockReport )、缓存数据块汇报信息(CacheReport)增量数据块块汇报信息。响应NameNode返回的指令,如复制、删除、创建数据块指令。2.3 MapReduce2.3.1 MapReduce概念MapReduce将整个并行计算过程抽象到两个函数: A、Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。 B、Reduce(化简 归约):对一个列表的元素进行合并。一个简单的MapReduce程序只需要指定map()、reduce()、input和output,剩下的事由框架完成。MapReduce特点: A、易于编程 B、良好的扩展性 C、高容错性 D、适合PB级以上海量数据的离线处理相关概念: A、Job:用户的每一个计算请求,称为一个作业。 B、Task:每一个作业都需要拆开,交由多个服务器来完成,拆分出来的执行单位,就称为任务。YARN设计目标: A、通用的统一资源管理系统:同时运行长应用程序和短应用程序。 B、长应用程序:理论上永不停止运行,Service,http service等 C、短应用程序:短时间内会运行结束的程序,MR job,Spark job等。YARN服务组件: A、Client B、ResourceManager、Applicaton Master C、NodeManager、ContainerYARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave。2.4.1 ResourceManagerResourceManager负责对各个NodeManager上的资源进行统一管理和调度。整个集群只有一个。功能: A、处理客户端请求 B、启动/监控ApplicationMaster C、监控NodeManager D、资源分配与调度2.4.2 NodeManager整个集群有多个,负责单节点资源管理和使用。功能: A、单个节点上的资源管理和任务管理 B、处理来自ResourceManager的命令 C、处理来自ApplicationMaster的命令NodeManager管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态。2.4.3 Application Master管理一个在YARN内运行的应用程序的每个实例功能: A、数据切分 B、为应用程序申请资源,并进一步分配给内部任务 C、任务监控与容错Applicaton Master负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务。2.4.4 ContainerYARN的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。功能: A、对任务运行环境的抽象 B、描述一系列信息 C、任务运行资源(节点、内存、CPU) D、任务启动命令 E、任务运行环境三、 系统分析3.1 HDFS-文件存储结构3.1.1 读数据Client -> NameNodeClient -> DataNode3.1.2 写数据Client -> NameNode Client -> DataNode图3-1 HDFS读写数据流程3.2 MapReduce过程框图3.2.1 Map和ReduceMap阶段并行处理输入数据Reduce阶段对Map结果进行汇总3.2.2 Shuffle连接Map 和 Reduce阶段Map shuffle
Client -> DataNode图3-1 HDFS读写数据流程3.2 MapReduce过程框图3.2.1 Map和ReduceMap阶段并行处理输入数据Reduce阶段对Map结果进行汇总3.2.2 Shuffle连接Map 和 Reduce阶段Map shuffle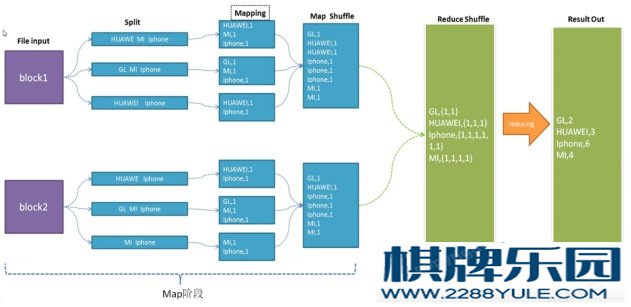 Reduce Shuffle图 3-2 MapReduce shuffle过程框图3.3 Yarn-虚拟操作系统/资源调度/任务管理3.3.1 集群资源的管理A、主节点-ResourceManagerB、从节点-NodeManager3.3.2 任务调度-三大进程A、ResourceManager (1)、处理客户端请求 (2)、启动、监控AppMaster (3)、监控NodeManager (4)、资源分配与调度B、NodeManager (1)、节点管理 (2)、处理来自ResManager的命令 (3)、处理来自AppMaster的命令C、ApplicationMaster (1)、申请资源 (2)、监控、管理NodeManager上任务运行情况
Reduce Shuffle图 3-2 MapReduce shuffle过程框图3.3 Yarn-虚拟操作系统/资源调度/任务管理3.3.1 集群资源的管理A、主节点-ResourceManagerB、从节点-NodeManager3.3.2 任务调度-三大进程A、ResourceManager (1)、处理客户端请求 (2)、启动、监控AppMaster (3)、监控NodeManager (4)、资源分配与调度B、NodeManager (1)、节点管理 (2)、处理来自ResManager的命令 (3)、处理来自AppMaster的命令C、ApplicationMaster (1)、申请资源 (2)、监控、管理NodeManager上任务运行情况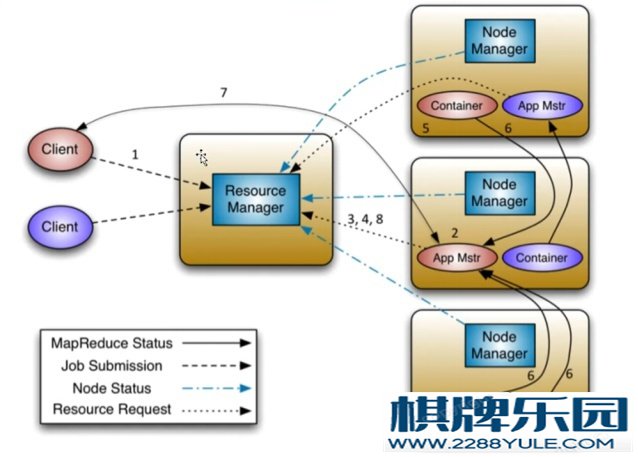 D、Container-对资源的抽象和封装图 3-3 ResourceManager运行过程四、 详细设计4.1 centos虚拟机搭建4.1.1 准备阶段A、VMware Workstation Pro15.5vm虚拟机是一个“虚拟PC”软件。它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,vm虚拟机采用了完全不同的概念。多启动系统在一个时刻只能运行一个系统,在系统切换时需要重新启动机器,随着该软件用户不断增加,从10.0以后就有各种的语言版本。软件特性:a、不需要分区或重开机就能在同一台计算机上使用两种以上的操作系统。b、完全隔离了另外的操作系统, 并且保护不同类型的操作系统的操作环境以及所有安装在操作系统上面的应用软件和资料。c、可在不同的操作系统之间能相互操作,包括网络、周边、文件共享以及复制、粘贴的多种功能。d、具有复原(Undo)功能。e、还能够随时设定、修改操作系统的操作环境,如:内存、磁盘空间、周边的设备等等。B、CentOS-7.0-1406-x86_64-DVD.isoCentOS(Community Enterprise Operating System,中文意思是社区企业操作系统)是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照开放源代码规定释出的源代码所编译而成。由于出自同样的源代码,因此有些要求高度稳定性的服务器以CentOS替代商业版的Red Hat Enterprise Linux使用。两者的不同,在于CentOS完全开源。CentOS 是一个基于Red Hat Linux 提供的可自由使用源代码的企业级Linux发行版本。每个版本的 CentOS都会获得十年的支持(通过安全更新方式)。新版本的 CentOS 大约每两年发行一次,而每个版本的 CentOS 会定期(大概每六个月)更新一次,以便支持新的硬件。这样,建立一个安全、低维护、稳定、高预测性、高重复性的 Linux 环境。CentOS是Community Enterprise Operating System的缩写。CentOS 是RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在RHEL的基础上修正了不少已知的 Bug ,相对于其他 Linux 发行版,其稳定性值得信赖。CentOS在2014初,宣布加入Red Hat。4.1.2 搭建步骤(1)、安装VMware Workstation Pro15.5并启动
D、Container-对资源的抽象和封装图 3-3 ResourceManager运行过程四、 详细设计4.1 centos虚拟机搭建4.1.1 准备阶段A、VMware Workstation Pro15.5vm虚拟机是一个“虚拟PC”软件。它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,vm虚拟机采用了完全不同的概念。多启动系统在一个时刻只能运行一个系统,在系统切换时需要重新启动机器,随着该软件用户不断增加,从10.0以后就有各种的语言版本。软件特性:a、不需要分区或重开机就能在同一台计算机上使用两种以上的操作系统。b、完全隔离了另外的操作系统, 并且保护不同类型的操作系统的操作环境以及所有安装在操作系统上面的应用软件和资料。c、可在不同的操作系统之间能相互操作,包括网络、周边、文件共享以及复制、粘贴的多种功能。d、具有复原(Undo)功能。e、还能够随时设定、修改操作系统的操作环境,如:内存、磁盘空间、周边的设备等等。B、CentOS-7.0-1406-x86_64-DVD.isoCentOS(Community Enterprise Operating System,中文意思是社区企业操作系统)是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照开放源代码规定释出的源代码所编译而成。由于出自同样的源代码,因此有些要求高度稳定性的服务器以CentOS替代商业版的Red Hat Enterprise Linux使用。两者的不同,在于CentOS完全开源。CentOS 是一个基于Red Hat Linux 提供的可自由使用源代码的企业级Linux发行版本。每个版本的 CentOS都会获得十年的支持(通过安全更新方式)。新版本的 CentOS 大约每两年发行一次,而每个版本的 CentOS 会定期(大概每六个月)更新一次,以便支持新的硬件。这样,建立一个安全、低维护、稳定、高预测性、高重复性的 Linux 环境。CentOS是Community Enterprise Operating System的缩写。CentOS 是RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在RHEL的基础上修正了不少已知的 Bug ,相对于其他 Linux 发行版,其稳定性值得信赖。CentOS在2014初,宣布加入Red Hat。4.1.2 搭建步骤(1)、安装VMware Workstation Pro15.5并启动 图 4-1 VM虚拟机界面
图 4-1 VM虚拟机界面 (2)、选择linux版本:centos7 64位图 4-2 选择Linux版本(3)、设置此虚拟机名为master.hadoop,紧接着一直点下一步,直到完成配置。(4)、选择ios文件位置
(2)、选择linux版本:centos7 64位图 4-2 选择Linux版本(3)、设置此虚拟机名为master.hadoop,紧接着一直点下一步,直到完成配置。(4)、选择ios文件位置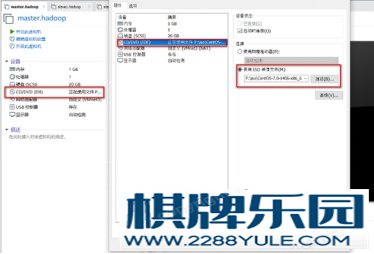 图4-3 配置ios文件(5)、配置好ios镜像文件后,启动master.hadoop,设置账户名,密码等。
图4-3 配置ios文件(5)、配置好ios镜像文件后,启动master.hadoop,设置账户名,密码等。 (6)、配置vm虚拟机虚拟网卡,自定义一个网段。我这里创建了一个VMnet3虚拟网卡,然后定义的是192.168.33.0网段,子网掩码为255.255.255.0,网关为192.168.33.2。图 4-4 配置ip地址(7)、右键虚拟机master.hadoop选择设置,网络适配器选择刚刚自定义的VMnet3虚拟网卡。
(6)、配置vm虚拟机虚拟网卡,自定义一个网段。我这里创建了一个VMnet3虚拟网卡,然后定义的是192.168.33.0网段,子网掩码为255.255.255.0,网关为192.168.33.2。图 4-4 配置ip地址(7)、右键虚拟机master.hadoop选择设置,网络适配器选择刚刚自定义的VMnet3虚拟网卡。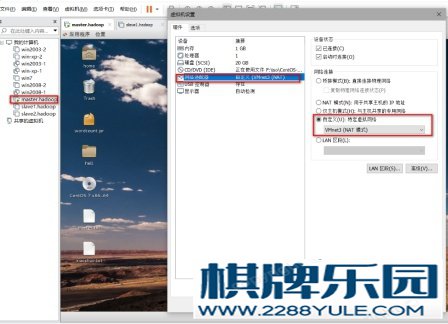 图4-5 配置虚拟网卡
图4-5 配置虚拟网卡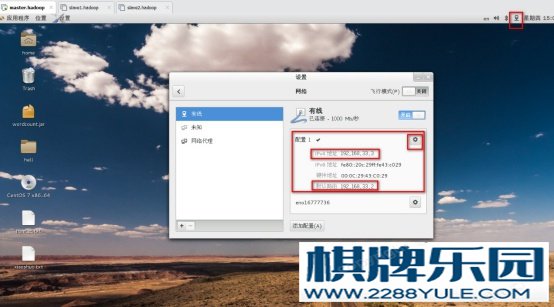 (8)、配置虚拟机master.hadoop的ip地址为192.168.33.3图 4-6 虚拟机选择虚拟网卡(9)、使用xshell连接虚拟机master.hadoop。新建一个连接,并填入刚刚设置的master.hadoop的ip地址。
(8)、配置虚拟机master.hadoop的ip地址为192.168.33.3图 4-6 虚拟机选择虚拟网卡(9)、使用xshell连接虚拟机master.hadoop。新建一个连接,并填入刚刚设置的master.hadoop的ip地址。 图4-7 xshell连接虚拟机(10)、xshell连接到master.hadoop虚拟机后,在命令行输入vi /etc/hostname配置master.hadoop的主机名为master.hadoop。配置完后输入hostname查看配置是否成功。
图4-7 xshell连接虚拟机(10)、xshell连接到master.hadoop虚拟机后,在命令行输入vi /etc/hostname配置master.hadoop的主机名为master.hadoop。配置完后输入hostname查看配置是否成功。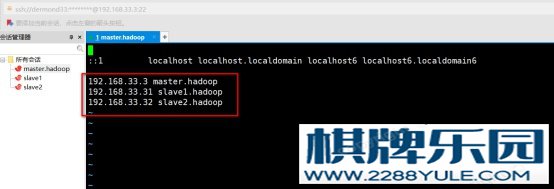 (11)、命令行输入vi /etc/hosts配置ip地址与虚拟机的映射。这里把另外两台计算机的映射一起配置好。图 4-8 配置三个虚拟机的映射(12)、命令行输入systemctl stop firewalld.service以及systemctl disable firewalld.service关闭虚拟机的防火墙。随后输入firewall-cmd –state查看防火墙是否关闭。
(11)、命令行输入vi /etc/hosts配置ip地址与虚拟机的映射。这里把另外两台计算机的映射一起配置好。图 4-8 配置三个虚拟机的映射(12)、命令行输入systemctl stop firewalld.service以及systemctl disable firewalld.service关闭虚拟机的防火墙。随后输入firewall-cmd –state查看防火墙是否关闭。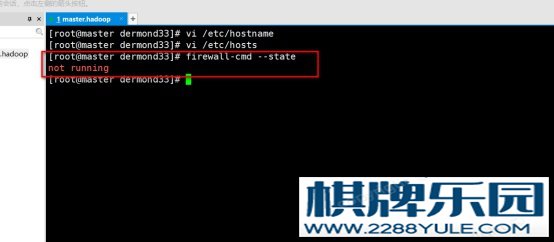 图4-9 关闭防火墙(13)、按照以上步骤安装剩下两台虚拟机slave1.hadoop和slave2.hadoop,分别设置ip地址为192.168.33.31和192.168.33.32。配置完成后相互ping,ping通则安装配置成功。4.2 hadoop集群搭建4.2.1 准备阶段A、hadoop2.7.0二进制安装包B、jdk二进制安装包 JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序。JDK是整个java开发的核心,它包含了JAVA的运行环境(JVM+Java系统类库)和JAVA工具。Javac:Java源程序编译器,将Java源代码转换成字节码。Java: Java解释器,直接从字节码文件,又称为类文件。执行Java应用程序的字节代码。jar:java应用程序打包工具,可将多个类文件合并为单个JAR归档文件。Javadoc:Java API文档生成器从Java源程序代码注释中提取文档,生成API文档HTML页。jdb:Java调试器(debugger),可以逐行执行程序.设置断点和检查变Md。jps:查看Java虚拟机进程列表。4.2.2 搭建步骤
图4-9 关闭防火墙(13)、按照以上步骤安装剩下两台虚拟机slave1.hadoop和slave2.hadoop,分别设置ip地址为192.168.33.31和192.168.33.32。配置完成后相互ping,ping通则安装配置成功。4.2 hadoop集群搭建4.2.1 准备阶段A、hadoop2.7.0二进制安装包B、jdk二进制安装包 JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序。JDK是整个java开发的核心,它包含了JAVA的运行环境(JVM+Java系统类库)和JAVA工具。Javac:Java源程序编译器,将Java源代码转换成字节码。Java: Java解释器,直接从字节码文件,又称为类文件。执行Java应用程序的字节代码。jar:java应用程序打包工具,可将多个类文件合并为单个JAR归档文件。Javadoc:Java API文档生成器从Java源程序代码注释中提取文档,生成API文档HTML页。jdb:Java调试器(debugger),可以逐行执行程序.设置断点和检查变Md。jps:查看Java虚拟机进程列表。4.2.2 搭建步骤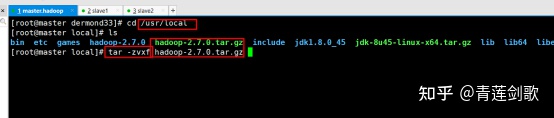 (1)、在master.hadoop虚拟机中使用tar -zxvf命令分别解压hadoop和jdk压缩包到/usr/local目录。图 4-10 解压缩二进制压缩包
(1)、在master.hadoop虚拟机中使用tar -zxvf命令分别解压hadoop和jdk压缩包到/usr/local目录。图 4-10 解压缩二进制压缩包 (2)、输入命令vi /etc/profile配置jdk和hadoop环境变量。配置完成后输入source /etc/profile使配置的环境变量生效。然后输入hadoop version以及java-version来查看安装是否成功,如果分别出现版本号,则配置成功。图 4-11 java以及hadoop环境配置(3)、配置core-site.xml
(2)、输入命令vi /etc/profile配置jdk和hadoop环境变量。配置完成后输入source /etc/profile使配置的环境变量生效。然后输入hadoop version以及java-version来查看安装是否成功,如果分别出现版本号,则配置成功。图 4-11 java以及hadoop环境配置(3)、配置core-site.xml 进入hadoop安装目录输入vi ./etc/hadoop/core-site.xml配置文件。图 4-12 core-site.xml配置(4)、配置hdfs-site.xml
进入hadoop安装目录输入vi ./etc/hadoop/core-site.xml配置文件。图 4-12 core-site.xml配置(4)、配置hdfs-site.xml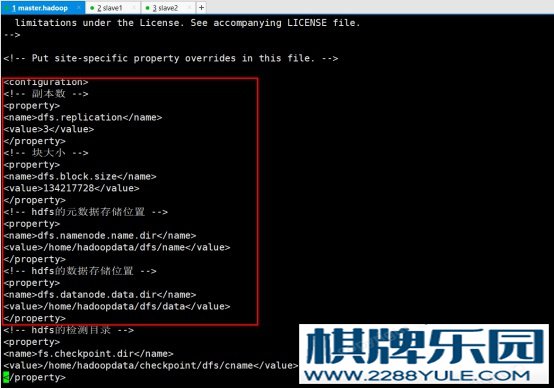 输入vi ./etc/hadoop/hdfs-site.xml进入配置文件。
输入vi ./etc/hadoop/hdfs-site.xml进入配置文件。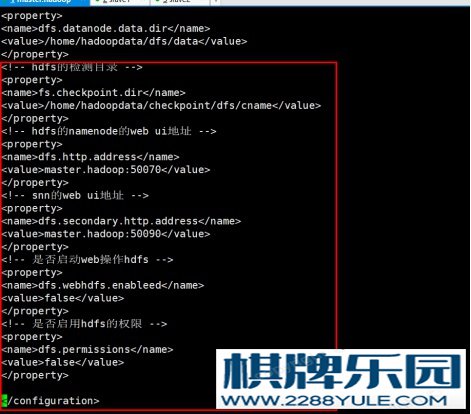 图4-13 hdfs-site.xml配置1图 4-14 hdfs-site.xml配置2(5)、配置mapred-site.xml
图4-13 hdfs-site.xml配置1图 4-14 hdfs-site.xml配置2(5)、配置mapred-site.xml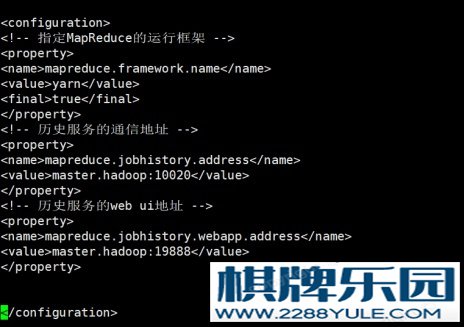 输入vi ./etc/hadoop/mapred-site.xml进入配置文件。图 4-15 mapred-site.xml配置(6)、配置yarn-site.xml
输入vi ./etc/hadoop/mapred-site.xml进入配置文件。图 4-15 mapred-site.xml配置(6)、配置yarn-site.xml 输入vi ./etc/hadoop/yarn-site.xml进入配置文件。图 4-16 yarn-site.xml配置1
输入vi ./etc/hadoop/yarn-site.xml进入配置文件。图 4-16 yarn-site.xml配置1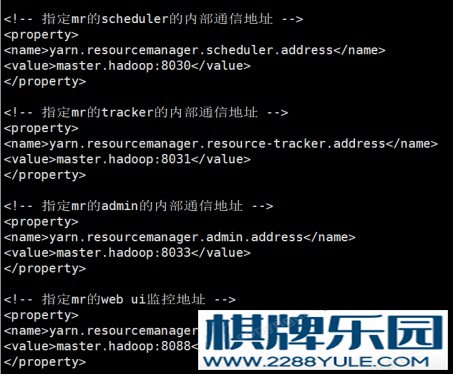 图4-17 yarn-site.xml配置2(7)、配置slave。
图4-17 yarn-site.xml配置2(7)、配置slave。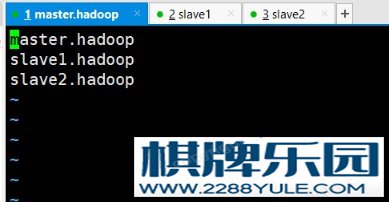 输入vi ./etc/hadoop/slaves进入配置文件。图 4-18 slave配置(8)、将刚刚在master.hadoop上配置的文件发送给slave1.hadoop以及slave2.hadoop虚拟机,并且在两台salve机上同样配置环境变量。分别输入命令:scp -r ../hadoop-2.7.0/ 192.168.33.31:/usr/localscp -r ../hadoop-2.7.0/ 192.168.33.32:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.31:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.32:/usr/local(9)、在namenode服务上格式化。输入命令:hadoop namenode -format4.2.3 服务分配根据上面的配置,三台计算机上的服务分配如下:表 4-1 三台主机任务分配主机名IP地址服务功能master.hadoop192.168.33.3Nodemanager、namenode、DataNode、ResourceManager、Secondarynamenodeslave1.hadoop192.168.33.31DataNode、nodemanagerslave2.hadoop192.168.33.32DataNode、nodemanager4.2.4 配置ssh免密登录在master.hadoop中依次输入:ssh-keygen -t rsassh-copy-id master.hadoopssh-copy-id slave1.hadoopssh-copy-id slave2.hadoop实现三台虚拟机ssh免密登录。4.2.5 启动hadoop集群进入hadoop安装目录,输入./sbin/start-all.sh启动hadoop集群。启动成功后在三台虚拟机上分别输入jps查看各自相应的服务功能是否都启动。
输入vi ./etc/hadoop/slaves进入配置文件。图 4-18 slave配置(8)、将刚刚在master.hadoop上配置的文件发送给slave1.hadoop以及slave2.hadoop虚拟机,并且在两台salve机上同样配置环境变量。分别输入命令:scp -r ../hadoop-2.7.0/ 192.168.33.31:/usr/localscp -r ../hadoop-2.7.0/ 192.168.33.32:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.31:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.32:/usr/local(9)、在namenode服务上格式化。输入命令:hadoop namenode -format4.2.3 服务分配根据上面的配置,三台计算机上的服务分配如下:表 4-1 三台主机任务分配主机名IP地址服务功能master.hadoop192.168.33.3Nodemanager、namenode、DataNode、ResourceManager、Secondarynamenodeslave1.hadoop192.168.33.31DataNode、nodemanagerslave2.hadoop192.168.33.32DataNode、nodemanager4.2.4 配置ssh免密登录在master.hadoop中依次输入:ssh-keygen -t rsassh-copy-id master.hadoopssh-copy-id slave1.hadoopssh-copy-id slave2.hadoop实现三台虚拟机ssh免密登录。4.2.5 启动hadoop集群进入hadoop安装目录,输入./sbin/start-all.sh启动hadoop集群。启动成功后在三台虚拟机上分别输入jps查看各自相应的服务功能是否都启动。 在宿主机浏览上输入192.168.33.3:50070以及192.168.33.3:8088。图 4-19 启动hadoop集群结果图4-20 8088端口网页图 4-21 50070端口网页4.3 Java操作hdfs文件系统4.3.1 maven配置(基于idea编辑器)在idea中新建一个maven项目,在项目中的prom.xml文件中配置hadoop需要的jar包。A、hadoop-commonB、hadoop-clientC、hadoop-hdfs4.3.2 编写java操作hdfs文件的代码
在宿主机浏览上输入192.168.33.3:50070以及192.168.33.3:8088。图 4-19 启动hadoop集群结果图4-20 8088端口网页图 4-21 50070端口网页4.3 Java操作hdfs文件系统4.3.1 maven配置(基于idea编辑器)在idea中新建一个maven项目,在项目中的prom.xml文件中配置hadoop需要的jar包。A、hadoop-commonB、hadoop-clientC、hadoop-hdfs4.3.2 编写java操作hdfs文件的代码 A、读取hdfs文件到windows目录的函数图 4-22 readFileToLocal函数
A、读取hdfs文件到windows目录的函数图 4-22 readFileToLocal函数 B、上传到hdfs文件的函数图 4-23 copyFromLocal函数
B、上传到hdfs文件的函数图 4-23 copyFromLocal函数 C、主函数图 4-24 main函数(具体代码见附录。)4.4 MapReduce编写词频统计jar包
C、主函数图 4-24 main函数(具体代码见附录。)4.4 MapReduce编写词频统计jar包 4.4.1 map函数图 4-25 map函数
4.4.1 map函数图 4-25 map函数 五、 程序测试5.1 上传目标文档hamlet.txt到hdfs5.1.1 准备文件en-hamlet.txt放到windows目录下E:\workspace\hadoopdata5.1.2 运行编写好的java操作hdfs文件的代码使用copyfromlocal函数上传windows文件到hdfs文件目录在xshell输入hdfs dfs -ls /查看en-hamlet.txt是否成功上传到hdfs的根目录。5.2 开始云计算词频统计5.2.1 xshell命令行执行刚才传到master.hadoop上的wordcount.jar执行命令为:yarn jar /home/wordcount.jar wordcount.MyWordCount /en-hamlet.txt /output/en-hamlet其中wordcount.MyWordCount为包名.类名/en-hamlet.txt为需要统计的哈姆雷特文章节选/output/en-hamlet为统计完之后输出的文件的目录,en-hamlet目录在云计算之前是没有的,统计完词汇后hadoop会自动创建这个en-hamlet文件夹。5.2.2 查看词频统计是否成功
五、 程序测试5.1 上传目标文档hamlet.txt到hdfs5.1.1 准备文件en-hamlet.txt放到windows目录下E:\workspace\hadoopdata5.1.2 运行编写好的java操作hdfs文件的代码使用copyfromlocal函数上传windows文件到hdfs文件目录在xshell输入hdfs dfs -ls /查看en-hamlet.txt是否成功上传到hdfs的根目录。5.2 开始云计算词频统计5.2.1 xshell命令行执行刚才传到master.hadoop上的wordcount.jar执行命令为:yarn jar /home/wordcount.jar wordcount.MyWordCount /en-hamlet.txt /output/en-hamlet其中wordcount.MyWordCount为包名.类名/en-hamlet.txt为需要统计的哈姆雷特文章节选/output/en-hamlet为统计完之后输出的文件的目录,en-hamlet目录在云计算之前是没有的,统计完词汇后hadoop会自动创建这个en-hamlet文件夹。5.2.2 查看词频统计是否成功 在宿主机的浏览器上输入192.168.33.3:8088查看图 5-2 8088网页端口查看结果如上图显示则执行成功此时,在xshell输入hdfs dfs -ls /output/en-hamlet/可以看见两个文件,分别为:_SUCCESS和part-r-00000。其中part-r-00000文件就是统计后的词频文件。5.3 下载结果文件到windows目录5.3.1 词频统计成功后需要把hdfs目录中的part-r-00000文件下载到windows目录查看
在宿主机的浏览器上输入192.168.33.3:8088查看图 5-2 8088网页端口查看结果如上图显示则执行成功此时,在xshell输入hdfs dfs -ls /output/en-hamlet/可以看见两个文件,分别为:_SUCCESS和part-r-00000。其中part-r-00000文件就是统计后的词频文件。5.3 下载结果文件到windows目录5.3.1 词频统计成功后需要把hdfs目录中的part-r-00000文件下载到windows目录查看 此时调用的是readfiletolocal函数,并把下载下来的文件命名为en-hamletwords.txt图 5-3 下载统计文件到本地目录
此时调用的是readfiletolocal函数,并把下载下来的文件命名为en-hamletwords.txt图 5-3 下载统计文件到本地目录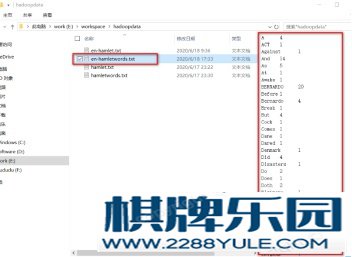 执行程序,成功后打开windows目录下对应的文件夹,就可以看到出现了一个叫en-hamletwords.txt的文件图 5-4 查看统计好的文件5.4 验证计算结果5.4.1 抽查MapReduce计算的词频数是否正确
执行程序,成功后打开windows目录下对应的文件夹,就可以看到出现了一个叫en-hamletwords.txt的文件图 5-4 查看统计好的文件5.4 验证计算结果5.4.1 抽查MapReduce计算的词频数是否正确 打开en-hamlet.txt,通过ctrl+f查找计数功能与en-hamletwords文件做对比。如上图所示,单词BERNARDO 通过MapReduce统计出了20次,通过ctrl+f功能验证也出现了20次,则MapReduce编程成功,完美的统计出了词频数.六、 设计总结这次课程设计统计了莎士比亚的哈姆雷特英文原版节选,统计英文词汇的切分是通过“ ”空格是来实现的,因为每个英文单词之间都用空格隔开。但是有些单词后面紧跟着标点符号就无法把标点符号分开统计了,我解决的办法是通过office的替换功能把标点符号都去掉了,但是在实际生活中是无法这样做的,更有效的分词方法还有待学习。另一个遇到的问题是中文词汇的统计,如果通过空格切分的方法,是无法统计每个汉字的个数的,因为汉字之间没有空格,当然也可以通过ofice的替换功能来给每个汉字之间添加空格,这种方法也只是在实验的阶段,无法运用到实际生活中,通过上网查阅资料发现可以使用IK分词包来统计汉字的词频数。通过本次的课程设计认识到了什么是hadoop,MapReduce编程实现词频统计的原理是什么,但这仅仅是云计算的入门,这次成功的课程设计让我对云计算产生了更大的兴趣,这也激励我更加的努力学习云计算技术。其次,我要感谢帮助过我的同班同学王福德,马宝旗等人,他们也为我解决了不少我不太明白的设计的难题。同时也感谢学院为我提供良好的做设计的环境。参考文献[1] 刘鹏. 实战Hadoop#:#开启通向云计算的捷径[M]. 电子工业出版社, 2011.[2] 唐国纯. 云计算及应用[M]. 清华大学出版社, 2015.[3] 程克非, 罗江华, 兰文富. 云计算基础教程[M]. 人民邮电出版社, 2013.[4] 万川梅, 谢正兰. 深入云计算:Hadoop应用开发实战详解[M]. 中国铁道出版社, 2014.[5] 周品. Hadoop云计算实战[M]. 清华大学出版社, 2012.[6] 叶晓江刘鹏. 实战Hadoop 2.0[专著] : 从云计算到大数据[M].[7] 陈全, 邓倩妮. 云计算及其关键技术[J]. 计算机应用, 2009(09):254-259.[8] 费珊珊. 基于云计算Hadoop平台的数据挖掘研究[D]. 北京邮电大学, 2014.
打开en-hamlet.txt,通过ctrl+f查找计数功能与en-hamletwords文件做对比。如上图所示,单词BERNARDO 通过MapReduce统计出了20次,通过ctrl+f功能验证也出现了20次,则MapReduce编程成功,完美的统计出了词频数.六、 设计总结这次课程设计统计了莎士比亚的哈姆雷特英文原版节选,统计英文词汇的切分是通过“ ”空格是来实现的,因为每个英文单词之间都用空格隔开。但是有些单词后面紧跟着标点符号就无法把标点符号分开统计了,我解决的办法是通过office的替换功能把标点符号都去掉了,但是在实际生活中是无法这样做的,更有效的分词方法还有待学习。另一个遇到的问题是中文词汇的统计,如果通过空格切分的方法,是无法统计每个汉字的个数的,因为汉字之间没有空格,当然也可以通过ofice的替换功能来给每个汉字之间添加空格,这种方法也只是在实验的阶段,无法运用到实际生活中,通过上网查阅资料发现可以使用IK分词包来统计汉字的词频数。通过本次的课程设计认识到了什么是hadoop,MapReduce编程实现词频统计的原理是什么,但这仅仅是云计算的入门,这次成功的课程设计让我对云计算产生了更大的兴趣,这也激励我更加的努力学习云计算技术。其次,我要感谢帮助过我的同班同学王福德,马宝旗等人,他们也为我解决了不少我不太明白的设计的难题。同时也感谢学院为我提供良好的做设计的环境。参考文献[1] 刘鹏. 实战Hadoop#:#开启通向云计算的捷径[M]. 电子工业出版社, 2011.[2] 唐国纯. 云计算及应用[M]. 清华大学出版社, 2015.[3] 程克非, 罗江华, 兰文富. 云计算基础教程[M]. 人民邮电出版社, 2013.[4] 万川梅, 谢正兰. 深入云计算:Hadoop应用开发实战详解[M]. 中国铁道出版社, 2014.[5] 周品. Hadoop云计算实战[M]. 清华大学出版社, 2012.[6] 叶晓江刘鹏. 实战Hadoop 2.0[专著] : 从云计算到大数据[M].[7] 陈全, 邓倩妮. 云计算及其关键技术[J]. 计算机应用, 2009(09):254-259.[8] 费珊珊. 基于云计算Hadoop平台的数据挖掘研究[D]. 北京邮电大学, 2014.
图2-1 HDFS结构2.2.1 namenodeNamenode是一个中心服务器,单一节点,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。Namenode负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过那么namenode,只会询问它跟那个datanode联系,否则namenode会成为系统的瓶颈。副本存放在哪个datanode由namenode控制,根据全局情况作出块放置决定,读取文件时namenode尽量让用户读取最近的副本,降低带块消耗和读取时延。Namenode全权管理数据块的复制,它周期性地从集群中的每个datanode接收心跳信号和块状态宝报告(blockreport)。接收到心跳信号意味着DataNode节点工作正常。块状态报告包含了一个该DataNode上所有数据块的列表。包含了两个核心的数据结构,FsImage和EditLog。FsImage:用于维护整个文件系统数以及文件树中所有的文件和文件夹的元数据EditLog:记录了所有针对文件的创建,删除,重命名等操作2.2.2 Secondary NameNode为主namenode内存中的文件系统元数据,创建检查点,在文件系统中设置一个检查点来帮助NameNode更好的工作,不是取代掉NameNode,也不是备份SecondayName有两个作用一是镜像备份,二是日志与镜像的定期合并。两个同时进行称为checkpoint。镜像备份的作用:备份fsImage合并作用:防止如果NameNode节点故障,namenode下次启动时,会把fsImage加载到内存中,应用editLog,EditLog往往很大,可以减少重启时间,同时保证HDFS系统的完整性。2.2.3 datanodeDatanode是HDFS文件系统的工作节点,它们根据客户端或者是namenode的调度进行存储和检索数据,并且定期向namenode发送它们所存储的块(block)的列表。Datanode以存储数据块(Block)的形式保存HDFS文件。响应客户端的读写文件请求。定期向NameNode汇报心跳信息、数据块汇报信息(BlockReport )、缓存数据块汇报信息(CacheReport)增量数据块块汇报信息。响应NameNode返回的指令,如复制、删除、创建数据块指令。2.3 MapReduce2.3.1 MapReduce概念MapReduce将整个并行计算过程抽象到两个函数: A、Map(映射):对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。 B、Reduce(化简 归约):对一个列表的元素进行合并。一个简单的MapReduce程序只需要指定map()、reduce()、input和output,剩下的事由框架完成。MapReduce特点: A、易于编程 B、良好的扩展性 C、高容错性 D、适合PB级以上海量数据的离线处理相关概念: A、Job:用户的每一个计算请求,称为一个作业。 B、Task:每一个作业都需要拆开,交由多个服务器来完成,拆分出来的执行单位,就称为任务。YARN设计目标: A、通用的统一资源管理系统:同时运行长应用程序和短应用程序。 B、长应用程序:理论上永不停止运行,Service,http service等 C、短应用程序:短时间内会运行结束的程序,MR job,Spark job等。YARN服务组件: A、Client B、ResourceManager、Applicaton Master C、NodeManager、ContainerYARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave。2.4.1 ResourceManagerResourceManager负责对各个NodeManager上的资源进行统一管理和调度。整个集群只有一个。功能: A、处理客户端请求 B、启动/监控ApplicationMaster C、监控NodeManager D、资源分配与调度2.4.2 NodeManager整个集群有多个,负责单节点资源管理和使用。功能: A、单个节点上的资源管理和任务管理 B、处理来自ResourceManager的命令 C、处理来自ApplicationMaster的命令NodeManager管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态。2.4.3 Application Master管理一个在YARN内运行的应用程序的每个实例功能: A、数据切分 B、为应用程序申请资源,并进一步分配给内部任务 C、任务监控与容错Applicaton Master负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务。2.4.4 ContainerYARN的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。功能: A、对任务运行环境的抽象 B、描述一系列信息 C、任务运行资源(节点、内存、CPU) D、任务启动命令 E、任务运行环境三、 系统分析3.1 HDFS-文件存储结构3.1.1 读数据Client -> NameNodeClient -> DataNode3.1.2 写数据Client -> NameNodeClient -> DataNode图3-1 HDFS读写数据流程3.2 MapReduce过程框图3.2.1 Map和ReduceMap阶段并行处理输入数据Reduce阶段对Map结果进行汇总3.2.2 Shuffle连接Map 和 Reduce阶段Map shuffleReduce Shuffle图 3-2 MapReduce shuffle过程框图3.3 Yarn-虚拟操作系统/资源调度/任务管理3.3.1 集群资源的管理A、主节点-ResourceManagerB、从节点-NodeManager3.3.2 任务调度-三大进程A、ResourceManager (1)、处理客户端请求 (2)、启动、监控AppMaster (3)、监控NodeManager (4)、资源分配与调度B、NodeManager (1)、节点管理 (2)、处理来自ResManager的命令 (3)、处理来自AppMaster的命令C、ApplicationMaster (1)、申请资源 (2)、监控、管理NodeManager上任务运行情况D、Container-对资源的抽象和封装图 3-3 ResourceManager运行过程四、 详细设计4.1 centos虚拟机搭建4.1.1 准备阶段A、VMware Workstation Pro15.5vm虚拟机是一个“虚拟PC”软件。它使你可以在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。与“多启动”系统相比,vm虚拟机采用了完全不同的概念。多启动系统在一个时刻只能运行一个系统,在系统切换时需要重新启动机器,随着该软件用户不断增加,从10.0以后就有各种的语言版本。软件特性:a、不需要分区或重开机就能在同一台计算机上使用两种以上的操作系统。b、完全隔离了另外的操作系统, 并且保护不同类型的操作系统的操作环境以及所有安装在操作系统上面的应用软件和资料。c、可在不同的操作系统之间能相互操作,包括网络、周边、文件共享以及复制、粘贴的多种功能。d、具有复原(Undo)功能。e、还能够随时设定、修改操作系统的操作环境,如:内存、磁盘空间、周边的设备等等。B、CentOS-7.0-1406-x86_64-DVD.isoCentOS(Community Enterprise Operating System,中文意思是社区企业操作系统)是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照开放源代码规定释出的源代码所编译而成。由于出自同样的源代码,因此有些要求高度稳定性的服务器以CentOS替代商业版的Red Hat Enterprise Linux使用。两者的不同,在于CentOS完全开源。CentOS 是一个基于Red Hat Linux 提供的可自由使用源代码的企业级Linux发行版本。每个版本的 CentOS都会获得十年的支持(通过安全更新方式)。新版本的 CentOS 大约每两年发行一次,而每个版本的 CentOS 会定期(大概每六个月)更新一次,以便支持新的硬件。这样,建立一个安全、低维护、稳定、高预测性、高重复性的 Linux 环境。CentOS是Community Enterprise Operating System的缩写。CentOS 是RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在RHEL的基础上修正了不少已知的 Bug ,相对于其他 Linux 发行版,其稳定性值得信赖。CentOS在2014初,宣布加入Red Hat。4.1.2 搭建步骤(1)、安装VMware Workstation Pro15.5并启动图 4-1 VM虚拟机界面(2)、选择linux版本:centos7 64位图 4-2 选择Linux版本(3)、设置此虚拟机名为master.hadoop,紧接着一直点下一步,直到完成配置。(4)、选择ios文件位置图4-3 配置ios文件(5)、配置好ios镜像文件后,启动master.hadoop,设置账户名,密码等。(6)、配置vm虚拟机虚拟网卡,自定义一个网段。我这里创建了一个VMnet3虚拟网卡,然后定义的是192.168.33.0网段,子网掩码为255.255.255.0,网关为192.168.33.2。图 4-4 配置ip地址(7)、右键虚拟机master.hadoop选择设置,网络适配器选择刚刚自定义的VMnet3虚拟网卡。图4-5 配置虚拟网卡(8)、配置虚拟机master.hadoop的ip地址为192.168.33.3图 4-6 虚拟机选择虚拟网卡(9)、使用xshell连接虚拟机master.hadoop。新建一个连接,并填入刚刚设置的master.hadoop的ip地址。图4-7 xshell连接虚拟机(10)、xshell连接到master.hadoop虚拟机后,在命令行输入vi /etc/hostname配置master.hadoop的主机名为master.hadoop。配置完后输入hostname查看配置是否成功。(11)、命令行输入vi /etc/hosts配置ip地址与虚拟机的映射。这里把另外两台计算机的映射一起配置好。图 4-8 配置三个虚拟机的映射(12)、命令行输入systemctl stop firewalld.service以及systemctl disable firewalld.service关闭虚拟机的防火墙。随后输入firewall-cmd –state查看防火墙是否关闭。图4-9 关闭防火墙(13)、按照以上步骤安装剩下两台虚拟机slave1.hadoop和slave2.hadoop,分别设置ip地址为192.168.33.31和192.168.33.32。配置完成后相互ping,ping通则安装配置成功。4.2 hadoop集群搭建4.2.1 准备阶段A、hadoop2.7.0二进制安装包B、jdk二进制安装包 JDK是 Java 语言的软件开发工具包,主要用于移动设备、嵌入式设备上的java应用程序。JDK是整个java开发的核心,它包含了JAVA的运行环境(JVM+Java系统类库)和JAVA工具。Javac:Java源程序编译器,将Java源代码转换成字节码。Java: Java解释器,直接从字节码文件,又称为类文件。执行Java应用程序的字节代码。jar:java应用程序打包工具,可将多个类文件合并为单个JAR归档文件。Javadoc:Java API文档生成器从Java源程序代码注释中提取文档,生成API文档HTML页。jdb:Java调试器(debugger),可以逐行执行程序.设置断点和检查变Md。jps:查看Java虚拟机进程列表。4.2.2 搭建步骤(1)、在master.hadoop虚拟机中使用tar -zxvf命令分别解压hadoop和jdk压缩包到/usr/local目录。图 4-10 解压缩二进制压缩包(2)、输入命令vi /etc/profile配置jdk和hadoop环境变量。配置完成后输入source /etc/profile使配置的环境变量生效。然后输入hadoop version以及java-version来查看安装是否成功,如果分别出现版本号,则配置成功。图 4-11 java以及hadoop环境配置(3)、配置core-site.xml进入hadoop安装目录输入vi ./etc/hadoop/core-site.xml配置文件。图 4-12 core-site.xml配置(4)、配置hdfs-site.xml输入vi ./etc/hadoop/hdfs-site.xml进入配置文件。图4-13 hdfs-site.xml配置1图 4-14 hdfs-site.xml配置2(5)、配置mapred-site.xml输入vi ./etc/hadoop/mapred-site.xml进入配置文件。图 4-15 mapred-site.xml配置(6)、配置yarn-site.xml输入vi ./etc/hadoop/yarn-site.xml进入配置文件。图 4-16 yarn-site.xml配置1图4-17 yarn-site.xml配置2(7)、配置slave。输入vi ./etc/hadoop/slaves进入配置文件。图 4-18 slave配置(8)、将刚刚在master.hadoop上配置的文件发送给slave1.hadoop以及slave2.hadoop虚拟机,并且在两台salve机上同样配置环境变量。分别输入命令:scp -r ../hadoop-2.7.0/ 192.168.33.31:/usr/localscp -r ../hadoop-2.7.0/ 192.168.33.32:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.31:/usr/localscp -r ../jdk1.8.0_45/ 192.168.33.32:/usr/local(9)、在namenode服务上格式化。输入命令:hadoop namenode -format4.2.3 服务分配根据上面的配置,三台计算机上的服务分配如下:表 4-1 三台主机任务分配主机名IP地址服务功能master.hadoop192.168.33.3Nodemanager、namenode、DataNode、ResourceManager、Secondarynamenodeslave1.hadoop192.168.33.31DataNode、nodemanagerslave2.hadoop192.168.33.32DataNode、nodemanager4.2.4 配置ssh免密登录在master.hadoop中依次输入:ssh-keygen -t rsassh-copy-id master.hadoopssh-copy-id slave1.hadoopssh-copy-id slave2.hadoop实现三台虚拟机ssh免密登录。4.2.5 启动hadoop集群进入hadoop安装目录,输入./sbin/start-all.sh启动hadoop集群。启动成功后在三台虚拟机上分别输入jps查看各自相应的服务功能是否都启动。在宿主机浏览上输入192.168.33.3:50070以及192.168.33.3:8088。图 4-19 启动hadoop集群结果图4-20 8088端口网页图 4-21 50070端口网页4.3 Java操作hdfs文件系统4.3.1 maven配置(基于idea编辑器)在idea中新建一个maven项目,在项目中的prom.xml文件中配置hadoop需要的jar包。A、hadoop-commonB、hadoop-clientC、hadoop-hdfs4.3.2 编写java操作hdfs文件的代码A、读取hdfs文件到windows目录的函数图 4-22 readFileToLocal函数B、上传到hdfs文件的函数图 4-23 copyFromLocal函数C、主函数图 4-24 main函数(具体代码见附录。)4.4 MapReduce编写词频统计jar包4.4.1 map函数图 4-25 map函数五、 程序测试5.1 上传目标文档hamlet.txt到hdfs5.1.1 准备文件en-hamlet.txt放到windows目录下E:\workspace\hadoopdata5.1.2 运行编写好的java操作hdfs文件的代码使用copyfromlocal函数上传windows文件到hdfs文件目录在xshell输入hdfs dfs -ls /查看en-hamlet.txt是否成功上传到hdfs的根目录。5.2 开始云计算词频统计5.2.1 xshell命令行执行刚才传到master.hadoop上的wordcount.jar执行命令为:yarn jar /home/wordcount.jar wordcount.MyWordCount /en-hamlet.txt /output/en-hamlet其中wordcount.MyWordCount为包名.类名/en-hamlet.txt为需要统计的哈姆雷特文章节选/output/en-hamlet为统计完之后输出的文件的目录,en-hamlet目录在云计算之前是没有的,统计完词汇后hadoop会自动创建这个en-hamlet文件夹。5.2.2 查看词频统计是否成功在宿主机的浏览器上输入192.168.33.3:8088查看图 5-2 8088网页端口查看结果如上图显示则执行成功此时,在xshell输入hdfs dfs -ls /output/en-hamlet/可以看见两个文件,分别为:_SUCCESS和part-r-00000。其中part-r-00000文件就是统计后的词频文件。5.3 下载结果文件到windows目录5.3.1 词频统计成功后需要把hdfs目录中的part-r-00000文件下载到windows目录查看此时调用的是readfiletolocal函数,并把下载下来的文件命名为en-hamletwords.txt图 5-3 下载统计文件到本地目录执行程序,成功后打开windows目录下对应的文件夹,就可以看到出现了一个叫en-hamletwords.txt的文件图 5-4 查看统计好的文件5.4 验证计算结果5.4.1 抽查MapReduce计算的词频数是否正确打开en-hamlet.txt,通过ctrl+f查找计数功能与en-hamletwords文件做对比。如上图所示,单词BERNARDO 通过MapReduce统计出了20次,通过ctrl+f功能验证也出现了20次,则MapReduce编程成功,完美的统计出了词频数.六、 设计总结这次课程设计统计了莎士比亚的哈姆雷特英文原版节选,统计英文词汇的切分是通过“ ”空格是来实现的,因为每个英文单词之间都用空格隔开。但是有些单词后面紧跟着标点符号就无法把标点符号分开统计了,我解决的办法是通过office的替换功能把标点符号都去掉了,但是在实际生活中是无法这样做的,更有效的分词方法还有待学习。另一个遇到的问题是中文词汇的统计,如果通过空格切分的方法,是无法统计每个汉字的个数的,因为汉字之间没有空格,当然也可以通过ofice的替换功能来给每个汉字之间添加空格,这种方法也只是在实验的阶段,无法运用到实际生活中,通过上网查阅资料发现可以使用IK分词包来统计汉字的词频数。通过本次的课程设计认识到了什么是hadoop,MapReduce编程实现词频统计的原理是什么,但这仅仅是云计算的入门,这次成功的课程设计让我对云计算产生了更大的兴趣,这也激励我更加的努力学习云计算技术。其次,我要感谢帮助过我的同班同学王福德,马宝旗等人,他们也为我解决了不少我不太明白的设计的难题。同时也感谢学院为我提供良好的做设计的环境。参考文献[1] 刘鹏. 实战Hadoop#:#开启通向云计算的捷径[M]. 电子工业出版社, 2011.[2] 唐国纯. 云计算及应用[M]. 清华大学出版社, 2015.[3] 程克非, 罗江华, 兰文富. 云计算基础教程[M]. 人民邮电出版社, 2013.[4] 万川梅, 谢正兰. 深入云计算:Hadoop应用开发实战详解[M]. 中国铁道出版社, 2014.[5] 周品. Hadoop云计算实战[M]. 清华大学出版社, 2012.[6] 叶晓江刘鹏. 实战Hadoop 2.0[专著] : 从云计算到大数据[M].[7] 陈全, 邓倩妮. 云计算及其关键技术[J]. 计算机应用, 2009(09):254-259.[8] 费珊珊. 基于云计算Hadoop平台的数据挖掘研究[D]. 北京邮电大学, 2014.
当新抓进的牌使顺子变为四连顺后,看哪头的顺子对牌局有帮助,就留哪头。如:二、三、四、五万棋牌百科,若二、三、四万顺子可与其它的牌组成番种,即留二万棋牌百科,舍五万;若三、四、五万顺子与别的牌组成番种后得分更多,当然要留五万打二万。
友情链接:
Powered by 麻将游戏 @2013-2022 RSS地图 HTML地图
网站统计——


